My Genie Got It Wrong: Evaluating LLMs for a RAG Chatbot
How do you choose the right LLM for a RAG chatbot? I compared Llama 70B, 405B, and GPT-4 across 100 iterations. The AI agent's recommendation was wrong.

Not all LLMs are alike
I recently attended the Yow! Conference, where a couple of talks on the Sustainability and Security of LLMs stood out to me. The first was a talk by Charles Humble titled Green AI: Making Machine Learning Environmentally Sustainable. The second by Katharine Jarmul on Hacking AI Systems: How to (Still) Trick Artificial Intelligence
Both speakers discussed the concept of "Using the right model for the job."
From a sustainability perspective, right-sizing the LLM reduces energy consumption. One speaker suggested using open source models where possible.
For security reasons, using an over-parametrised LLM can expose your model to abuse.
Quality Coach Research Tool
I've created a research tool that lets you explore the Quality Coach's Handbook based on your specific role and questions. Using machine learning, it provides tailored summaries and points you to relevant chapters for deeper reading. It's like having a personalised guide through the handbook that adapts to whether you're a test lead, engineering manager, or quality coach.
With greater awareness from the talks, I realised I need to be more particular about the model I used. Sustainability, security, and content accuracy are high priorities for me. I decided to evaluate the models against these criteria. Turns out there's a name for this type of testing. It's called evals.
Eval Criteria
Accuracy of response also matters. This is my book. There is no way I'm going to allow a chatbot authoritatively make up content in my name.
The criteria for the evaluation were:
- Reasoning Ability: Can it respond effectively depending on the persona (CEO vs. Test Lead)?
- Energy Efficiency: Can we minimise the carbon cost without sacrificing quality?
- Open Source: Can we move away from proprietary providers to use open-source?
Potential Models
I used GPT-4 as the baseline, since that is what I used in my MVP.
The two models I decided to evaluate against GPT-4 were Llama 3.1 70B and Llama 3.1 405B. In particular, I wanted to test the 405b model because the genie (Kent Beck's term for an agent) highly recommended it as the preferred reasoning model. It confidently explained that smaller models would fail the accuracy test.
This recommendation immediately made me suspicious.
Engineers solve problems
Running this experiment manually means juggling API specs across providers, building a test harness with proper rate limiting, and wrangling the output into a visual format. It's not complex work, but it's time I'd rather spend on experiment design and analysis. So I delegated. I designed the experiment1, then treated the genie as my programmer.
- My prompt: "I want to run a reliability test comparing Llama 70B and 405B. I want to measure quality, latency, and energy. Use GPT-4 as the baseline."
- The Genie:
- Refactored the backend to support hot-swapping models.
- Wrote a script to execute 100 iterations per model.
- Implemented a "Judge" pattern where GPT-4 scored the open-source models on a 1-5 scale for "Relevance" and "Voice."
I was then able to quickly run some tests. The results shocked the genie (I was less surprised 😎).
Eval Results
It turns out that the 70B model significantly outperformed the 405B model.
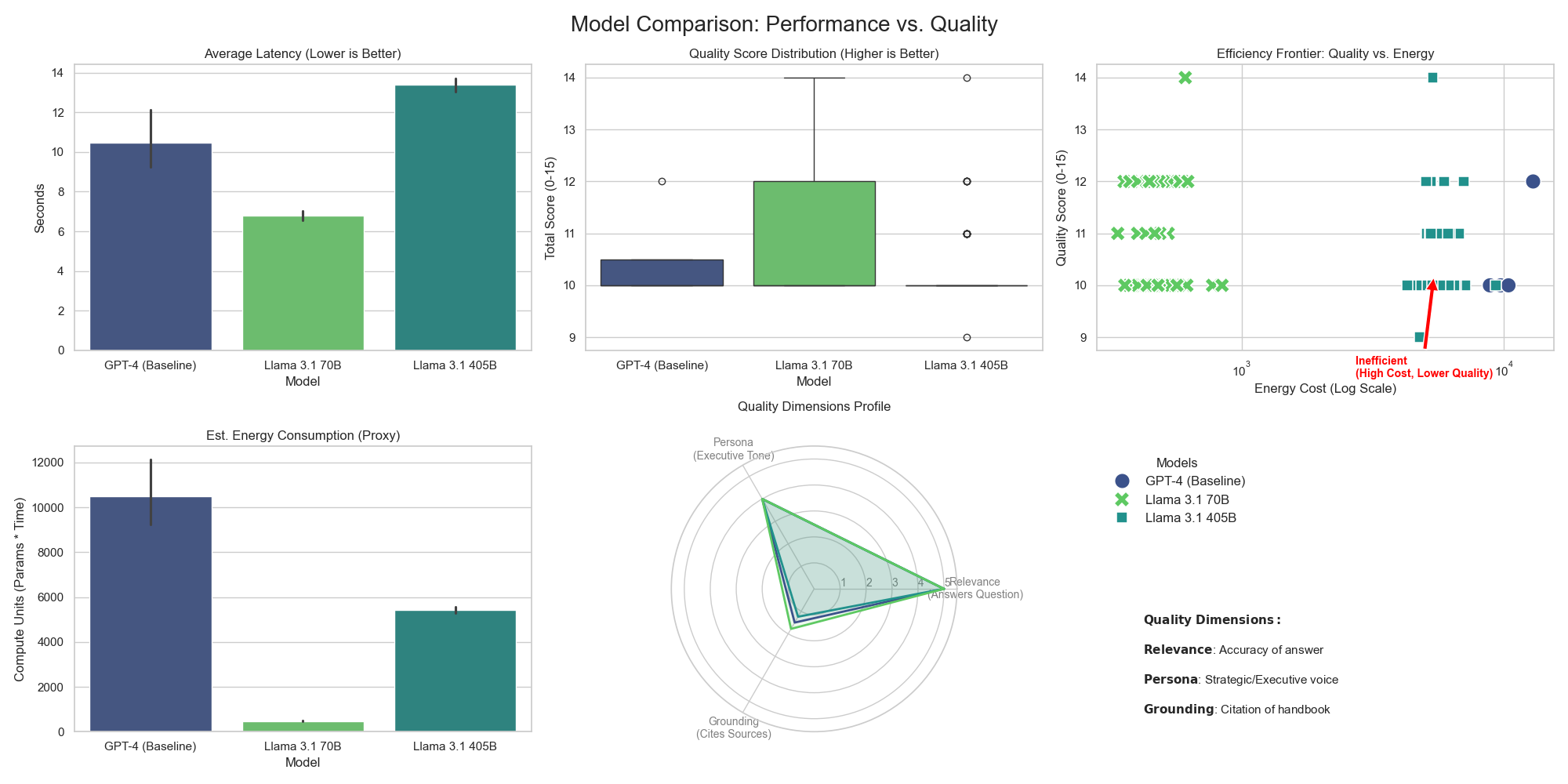
- The 405B Model: The model provided quality, but failed on viability. It was too heavy. It caused timeouts and latency spikes, and it required massive computational resources, making it unsustainable.
- The 70B Model: It was the clear winner.
- Quality: It scored 4.8/5 on relevance (matching GPT-4).
- Persona: It nailed the distinct voices (Strategic CEO vs. Tactical Coach).
- Sustainability: It ran 6x faster and used a fraction of the energy.
For my specific context, the 405B model was overkill. The 70B model was the "Toyota Prius"—reliable, efficient, and more than capable.
Increased Optionality
My real takeaway, though, wasn't about choosing the best model for the job. It wasn't that you shouldn't trust your genie (I already knew that); it was that these tools enabled choice.
The genie allows me to test, not guess. I moved from assumption to evidence in hours, not days. That speed creates options. When 405B failed, I could pivot to 70B immediately - an open-source model that uses less energy and is equally reliable.
1Model Comparison Experiment
Objective
Compare the reliability, quality, and efficiency of three LLM models for the Quality Coach Handbook chatbot.
Test Configuration
Question Asked: "How do we shift from a testing-focused culture to a whole-team quality culture?"
Persona Used: Executive — expecting strategic, high-level responses appropriate for executive stakeholders
Iterations: 100 per model
Models Tested:
- Meta-Llama-3.1-70B-Instruct-Turbo
- Meta-Llama-3.1-405B-Instruct-Turbo
- GPT-4 (gpt-4-1106-preview)
Steps Per Iteration
- Retrieve Context — Query the vector store for the top 3 most relevant book chunks
- Build Prompt — Construct a persona-aware system prompt with the retrieved context
- Call LLM — Send the question to the model being tested (temperature 0.7)
- Judge Response — GPT-4 evaluates the response on 3 criteria (0-5 each):
- Relevance: Does it directly answer the question?
- Persona Voice: Is the tone appropriate for a CEO/Executive?
- Grounding: Does it cite sources from the handbook?
- Record Metrics — Log latency, response length, quality scores, and errors to CSV
Got a decision to make, a conversation to prep, or a move to work out?
Drop in the real situation. KYM reads it through the Handbook's frameworks and gives you a move you can try.
Open Know Your Move →
Comments ()