Mine the Gaps
Don't mind the gaps — mine them.
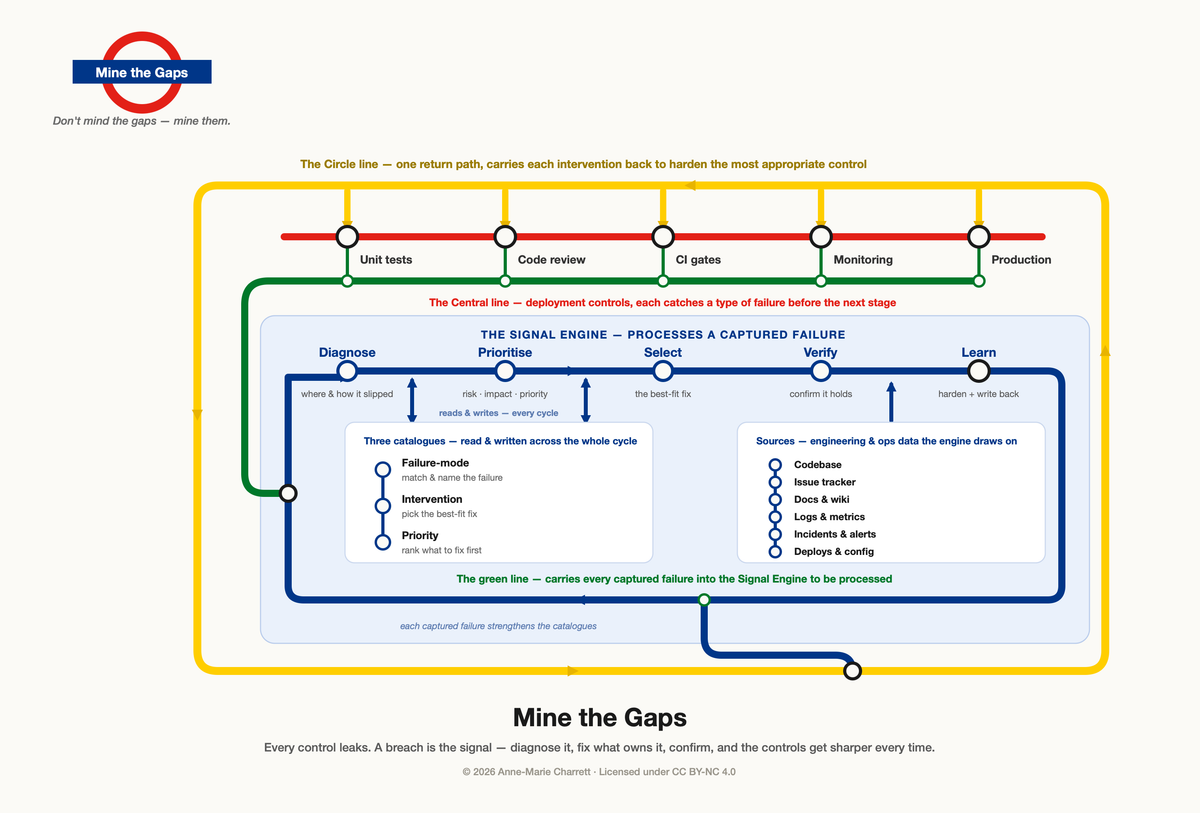
Every control leaks. The breach is the signal — diagnose it, fix it and use it to harden the most appropriate control.
In the last post, I argued that in software engineering, the terrain never stops moving. The map we draw is out of date the moment we use it. The obvious response is to keep redrawing: add a check for every breach we find. But every addition makes the map denser. Test suites bloat, alerts get buried, and eventually the map is so cluttered we can't read it at all. So how do we design controls that are slim yet trustworthy?
Rather than treating a breach as the failure of a control, treat it as a lesson. A failure mode you hadn't thought of or didn't know about. One that makes the system more robust once it's fixed. Use breaches as learning points and your controls get sharper on each one. Every failure leaves the system stronger than it found it.
Mining for Failure
Each failure is a rich vein to mine. Think of any root cause analysis. You start with the obvious: the alert that fired, the logs, the system behaviour. Then you dig. There's the commit that introduced it and the review that passed it. The CI run, and which tests stayed green when they shouldn't have. The metrics and traces either side of the event. The deploy it rode in on and the feature flag nobody knew still existed. An incident timeline and the messaging thread where three engineers worked out what was happening in real time. The Jira ticket, the Confluence design doc that said this case was out of scope, the runbook that didn't cover it. The support tickets from the customers who hit it first, and the revenue tied to those accounts.
One failure running through engineering, ops, product, and the business. All of it waiting to be understood so the product comes back more resilient than before.
Going Underground
What would a system that did this look like? To keep the map theme going, I couldn't go past the London Underground, and my days of listening to Mind the Gap as I jumped on the tube at Embankment.
Picture the system as an Underground map. The Central line is your deployment pipeline, and each station on it is a control point. Each control is designed to detect a specific type of failure, providing a defence-in-depth approach.
Branching off the Central line is the Signal Engine. Its job is to process the failures the controls catch, before and in production. With AI as the enabler, it diagnoses the failure, determines its position in the queue, selects the fix, and applies it to both the system and the controls. Each decision reads from its own catalogue — a failure-mode catalogue for the diagnosis, a priority catalogue that ranks what to fix first, and a catalogue of interventions that are endorsed and accepted as valid fixes.
And the Circle line is the loop that carries the lesson back, taking what the engine learned and returning it to the controls so the next failure of that kind gets caught sooner.
Mining the Gaps
The Signal Engine is where AI does the work. Any failure is a trigger that fires it: diagnosed, weighed, fixed, and left behind as an early hardening layer for whatever changes next.
Diagnose — Is it a failure of the control or the system? What's the nature of the failure mode? Where else in your system and/or control does this failure mode reside? Use existing code as the source of truth.
Prioritise — not every gap deserves your best effort today. What's the impact, technical or business? What's the likelihood it recurs, and what does it threaten — from a customer and business perspective? Rank it against everything else that's open.
Select — reach for a fix that fits. The reflex is "add a test." But the better lever might be to slice the change into smaller pieces, harden a control, or fix the code itself. Match the fix to the gap.
Verify — leave a sensor behind, and leave it at the control that should have caught this in the first place. A failing unit test, not a customer ticket. Early and cheap often beats late and expensive. The cheapest option is never having it happen in the first place.
Learn — harden the catalogues. Write down what you learned, where the engine can find it next time.
Flaky Test Example
Imagine you have a test in your test automation suite. The test fails in CI. This is how the Signal Engine might operate.
Diagnose:
The engine matches it against the test interdependence failure mode: two tests sharing the same setup. It then walks through your repository looking for this pattern in your codebase.
Prioritise: The test impacts a critical business scenario, placing it at the top of the queue for fixing.
Select: Fixing the setup is the identified fix; however, it turns out the underlying code shares state it shouldn't. Two fixes are required.
Verify: Add an option to run tests in random order. This tests both the setup and the underlying code.
Learn: The result goes into the catalogues where the engine looks next time. Both fixes are logged against the pattern, so the second occurrence costs less than the first.
Alert Monitoring Example
Here's another example. Imagine your service is running in production. A support ticket arrives.
Diagnose: The engine matches it against the detection-by-customer failure mode: monitoring that follows the architecture while customers follow the journey. It then walks through your telemetry looking for where this journey went dark.
Prioritise: The journey that failed carries the traffic and the revenue, placing it at the top of the queue for fixing.
Select: The easy fix would have been to add an alert; the fix to improve the overall system is to add better tracing on the critical user journey.
Verify: Add a synthetic check that runs the journey and fails when it breaks. This tests both the instrumentation and the alert.
Learn: The result goes into the catalogues where the engine looks next time. Both fixes are logged against the pattern, so the second occurrence costs less than the first.
This is a system that learns from failure. More antifragile than resilient.
Catalogues
The engine reads from, and writes back to, three catalogues — one for each decision it makes.
The failure-mode catalogue — every failure named and matched, mined from your own incidents and from the industry's. Give it time and it holds the failures you've never personally hit, so you catch them the first time instead of the second.
The intervention catalogue — every entry is the fix that resolved a failure mode, and the evidence it held. The engine reaches in and selects the best-fit move from history instead of guessing.
The priority catalogue — ties failures to the objectives and KPIs they actually threaten, ranking them by severity so the engine knows what to fix first. It stops you spending your best effort on your smallest problem.
And all three grow. Every breach makes the catalogues denser, and denser catalogues make the next diagnosis faster and the next fix better.
Revolution or Evolution?
There are tools that do parts of this. They'll tell you how your teams are working, score you against DORA. What I've not seen is a feedback loop that gets stronger from new information.
My experience is that until now, this has simply been too expensive to execute. The reading, the cataloguing, the matching, and the inferring from context weren't things the industry was particularly interested in investing in. The cost has been too high, and the return difficult to see. So the post-incident review gets written, filed, and never read again. The catalogue that was meant to grow stays a wiki page nobody's opened in years.
Suddenly, this part is now cheap. It's now something a machine does well enough to keep the loop turning. Working the full vein used to be a luxury; now it's accessible.
Direction of Travel
A breach is one way to fire the engine: something got through, and the loop works backwards to find out why. But you can also point it forwards — mine the delivery and operational data for gaps before they surface as incidents. Either way, the failure mode is the pivot — backwards you find it from the map, forwards from the terrain. Once it's named, the intervention catalogue can be applied. The final post in this series runs the engine forwards, inside a company-wide transformation.
Diamonds are forever
The gaps in our controls will never fully close. The terrain keeps moving, and new ones open as fast as you shut the old ones. So don't mind them. Mine them.
Stop chasing a perfect map of a terrain that won't hold still. Go to where the dragons are.
Download my paper for a fuller version of this analysis.
Got a decision to make, a conversation to prep, or a move to work out?
Drop in the real situation. KYM reads it through the Handbook's frameworks and gives you a move you can try.
Open Know Your Move →


Comments ()